上接《OpenCV3-Python人脸识别方法—基于摄像头》,实际应用中,有时我们不仅需要检测人脸信息,可能还需对识别到的人脸进行判断(是否是某个特定的人)?接下来,本篇介绍基于opencv的人脸数据采集和人物识别。
1. 人脸信息采集
人脸信息可通过两种方式获取:本地图像采集或从人脸数据库中获取;本文介绍本地图像采集的方式。
(1)采集流程
a. 打开摄像头,读取一帧图像。
b. 检测人脸,若检测到人脸信息,则裁剪灰度帧的区域,大小为200x200像素;
c. 保存文件到以此人名称命名的文件夹下,文件名后缀为.pgm
(2)源码
调用generate()函数时,需要根据实际情况更改函数参数。(例程中此参数对应为所采集信息的人的名称)
整个采集过程中,软件识别出人脸会自动编号保存,一般采集20张左右即可。
import cv2 import os def generate(dirname): face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_default.xml') eye_cascade = cv2.CascadeClassifier('./cascades/haarcascade_eye.xml') #eye_cascade = cv2.CascadeClassifier('./cascades/haarcascade_eye_tree_eyeglasses.xml') #创建目录 if(not os.path.isdir(dirname)): os.makedirs(dirname) #打开摄像头进行人脸图像采集 camera = cv2.VideoCapture(0) count = 0 while (True): ret, frame = camera.read() gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) faces = face_cascade.detectMultiScale(gray, 1.3, 5) for (x,y,w,h) in faces: img = cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2) #重设置图像尺寸 200*200 f = cv2.resize(gray[y:y+h, x:x+w], (200, 200)) cv2.imwrite(dirname+'/%s.pgm' % str(count), f) print(count) count += 1 cv2.imshow("camera", frame) if cv2.waitKey(100) & 0xff == ord("q"): break camera.release() cv2.destroyAllWindows() if __name__ == "__main__": generate("./data/lu") #根据实际需要修改,需先创建对应文件夹
(3)目录下保存的文件
2. 人脸识别
人脸识别一般有三种方法,它们分别基于不同算法:Eigenfaces、Fisherfaces和 Local Binary Pattern Histogram(LBPH)。
**Eigenfaces: **通过PCA来处理。PCA的本质是识别某个训练集上的主成分,并计算出训练集(图像或帧中的检测到的人脸)相对于数据库的发散程度,并输出一个值。该值越小,表明人脸数据库和检测到的人脸之间的差别就越小;0值表示完全匹配。
**Fisherfaces: **是从PCA中衍生发展出来的,采用更复杂的逻辑;尽管计算更加密集,但比Eigenfaces更容易得到准确效果。
**LBPH: **将检测到的人脸分为小单元,并将其与模型中的对应单元比较,对每个区域匹配值产生一个直方图。LBPH是唯一允许模型样本人脸和检测到的人脸在形状、大小上可以不同的人脸识别算法。
(1)识别流程
本文采用Eigenfaces模型进行人脸识别,流程如下:
a. 读取分类好的数据集,来进行“训练”;
b. 读取摄像头的实时人脸数据,通过算法进行人脸分析;
c. 若否识别到目标,则获取目标被识别到的置信度评分;
d. 根据置信度评分范围,判断目标是否被正确识别;
(2)源码
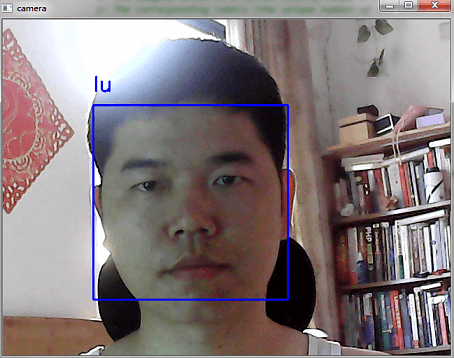
#!/usr/bin/env python # Software License Agreement (BSD License) # # Copyright (c) 2012, Philipp Wagner <bytefish[at]gmx[dot]de>. # All rights reserved. # # Redistribution and use in source and binary forms, with or without # modification, are permitted provided that the following conditions # are met: # # * Redistributions of source code must retain the above copyright # notice, this list of conditions and the following disclaimer. # * Redistributions in binary form must reproduce the above # copyright notice, this list of conditions and the following # disclaimer in the documentation and/or other materials provided # with the distribution. # * Neither the name of the author nor the names of its # contributors may be used to endorse or promote products derived # from this software without specific prior written permission. # # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS # "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT # LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS # FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE # COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, # INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, # BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT # LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN # ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE # POSSIBILITY OF SUCH DAMAGE. import os import sys import cv2 import numpy as np def read_images(path, sz=None): """Reads the images in a given folder, resizes images on the fly if size is given. Args: path: Path to a folder with subfolders representing the subjects (persons). sz: A tuple with the size Resizes Returns: A list [X,y] X: The images, which is a Python list of numpy arrays. y: The corresponding labels (the unique number of the subject, person) in a Python list. """ c = 0 X,y = [], [] names=[] for dirname, dirnames, filenames in os.walk(path): for subdirname in dirnames: subject_path = os.path.join(dirname, subdirname) for filename in os.listdir(subject_path): try: if (filename == ".directory"): continue filepath = os.path.join(subject_path, filename) im = cv2.imread(os.path.join(subject_path, filename), cv2.IMREAD_GRAYSCALE) if (im is None): print ("image " + filepath + " is none" ) # resize to given size (if given) if (sz is not None): im = cv2.resize(im, sz) X.append(np.asarray(im, dtype=np.uint8)) y.append(c) except: print ("Unexpected error:", sys.exc_info()[0]) raise c = c+1 names.append(subdirname) #添加对应的目录名称 return [names,X,y] def face_rec(): read_dir = "./data"; # Now read in the image data. This must be a valid path! [names,X,y] = read_images(read_dir) # Convert labels to 32bit integers. This is a workaround for 64bit machines, # because the labels will truncated else. This will be fixed in code as # soon as possible, so Python users don't need to know about this. # Thanks to Leo Dirac for reporting: y = np.asarray(y, dtype=np.int32) # Create the Eigenfaces model. We are going to use the default # parameters for this simple example, please read the documentation # for thresholding: #https://docs.opencv.org/3.0-beta/modules/face/doc/facerec/facerec_api.html?highlight=eigenfacerecognizer#Ptr<FaceRecognizer> createEigenFaceRecognizer(int num_components , double threshold) #注意:此函数新版发生变化 model = cv2.face_EigenFaceRecognizer.create() #Fisherfaces的人脸识别 #model = cv2.face_FisherFaceRecognizer.create() # Read # Learn the model. Remember our function returns Python lists, # so we use np.asarray to turn them into NumPy lists to make # the OpenCV wrapper happy: model.train(np.asarray(X), np.asarray(y)) camera = cv2.VideoCapture(0) face_cascade = cv2.CascadeClassifier('./cascades/haarcascade_frontalface_default.xml') while(True): read, img = camera.read() faces = face_cascade.detectMultiScale(img, 1.3, 5) for (x,y,w,h) in faces: img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2) gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) roi = gray[x:x+w, y:y+h] try: roi = cv2.resize(roi,(200,200),interpolation=cv2.INTER_LINEAR) # model.predict is going to return the predicted label and the associated confidence: [p_label, p_confidence] = model.predict(roi) # Print it: print ("Predicted label = %d (confidence=%.2f)" % (p_label, p_confidence)) #show name cv2.putText(img,names[p_label],(x,y-20),cv2.FONT_HERSHEY_SIMPLEX,1,255,2) except: continue cv2.imshow("camera", img) if cv2.waitKey(100) & 0xff == ord("q"): break camera.release() cv2.destroyAllWindows() if __name__ == "__main__": face_rec()
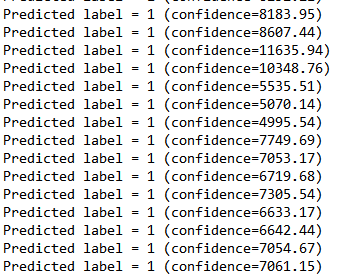
(3)识别结果
****(4)置信度评分****
predict()函数返回两个数组,第一个元素是识别个体的标签(之前提到的目录名称),第二个是置信度评分;实际应用中,可通过设置置信度评分的阈值,来达到更准确识别物体的目的。
Eigenfaces/Fisherfaces和LBPH的置信度评分值完全不同。Eigenfaces/Fisherfaces将产生0-20000的值,而任意低于4000到5000的评分都可认为是相当可靠的。